Het internet bestaat uit steeds meer shit
Update generatieve AI (deepfakes, LLM's) winter 2024
Synthetische (deepfake) video en audio ontwikkelden zich snel afgelopen jaar, maar dit viel nauwelijks op tussen de doorbraken op het gebied van tekst. Het afgelopen jaar ging alle aandacht uit naar grote taalmodellen (LLM’s) en in het bijzonder ChatGPT. Na de eerste opwinding over de schijnbaar eindeloze mogelijkheden werd duidelijk dat het als tekstgenerator eigenlijk maar een beperkt aantal betrouwbare toepassingsmogelijkheden en veel risico’s kent. Juridisch zijn er zelfs zoveel kanttekeningen dat niet gecontracteerd gebruik van online generatieve AI (tekst, beeld, geluid) voor rijksambtenaren in principe verboden is. Wanneer wordt gemak belangrijker dan de waarden van de rechtsstaat?
Dit hield mij bezig de afgelopen periode tijdens het schrijven van een notitie over de maatschappelijke impact van LLM’s. Vooral toen het nieuws naar buiten kwam dat een belangrijke dataset voor het trainen van tekst-to-image systemen kinderporno bevat . Dat is de reden waarom dergelijke tools nu ook gebruikt kunnen worden voor het genereren van kwalitatief goede virtuele kinderporno.
Al in 2022 was bekend dat de datasets beelden van ISIS-executies en ‘non consensual’ porno bevatten, maar deze werden niet offline gehaald. Nu is de dataset wel offline gehaald, maar dat geldt niet voor alle erop gebaseerde tools. Vanwege de complexiteit kiezen bedrijven vaak voor het aanpassen van de contentfilters om zo misbruik moeilijker te maken. Dit pleisters plakken zie je ook als reactie op alle problemen bij LLM’s. Het lost het oorspronkelijk probleem niet op en mensen blijven workarounds vinden om de nieuwe filters te omzeilen. Onderzoekers zijn er nu zelfs in geslaagd een AI
chatbot te trainen die zelf nieuwe methoden bedenkt om de contentfilters te ontwijken.
De techbedrijven nemen niet hun verantwoordelijkheid, ze zitten in een concurrentiestrijd waarbij het essentieel is zo snel mogelijk zoveel mogelijk gebruikers afhankelijk te maken. Dit kennen we van de sociale media. Moeten wij hen dan steunen door deze tools te gebruiken? Wat mij betreft nemen we hier een scherp standpunt op in om een andere koers af te dwingen.
Gebruik van deepfakes in de politiek normaliseert
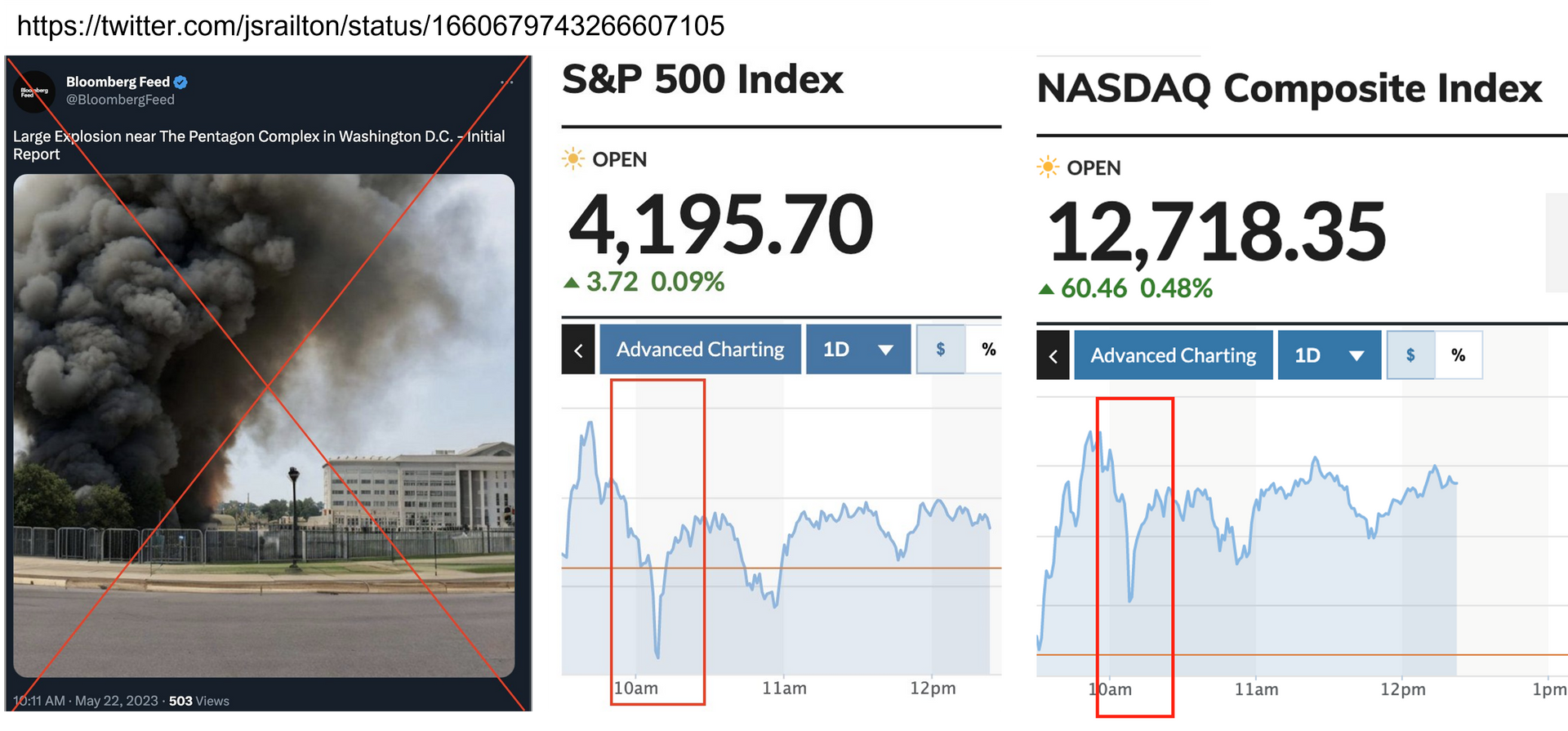
- Na de vele voorbeelden over deepfake beelden zoals van de Indonesie waar dictator Suharto, nu ook politieke tegenstanders die elkaars stem klonen om dingen te laten zeggen en desinformatie te verspreiden.
- Begin februari heeft een
democratische concurrent van Biden via een zogenaamd
robocall systeem massaal mensen laten bellen met de stem van
Biden om ze af te raden te gaan stemmen. Intussen heeft
Eleven Labs het account waarmee de voicekloon is gemaakt offline gehaald. Ook hier grijpen ze weer achteraf in, terwijl hun tool al veel ellende veroorzaakte, zo staat nog steeds het fragment online waarin een stemkloon van
actrice Emma Watson Mein Kampf voorleest.
- Je kunt het ook voor je laten werken. Er zijn vele voorbeelden, waaronder de burgemeester van New York die zijn stemkloon al sinds 2022 laat gebruiken om inwoners van de stad in hun eigen taal geautomatiseerd te bellen voor een gesprekje. Wees hier wel transparant over, mensen die hem tegenkomen op straat denken nu ten onrechte dat hij de talen Mandarijn, Creools, Spaans en Joods spreekt.
- De gevangen genomen oud premier Imran Khan van Pakistan gebruikte een stemkloon om vanachter de tralies toch campagne te kunnen voeren. Inmiddels heeft de deepfake kloon van Khan ook de verkiezingswinst opgeeist
Explosie deepporn dankzij Generatieve AI
- Eerder noemde ik al dat met AI goede kwaliteit kinderporno gegenereerd kan worden omdat het erop getraind is. Steeds vaker wordt generatieve AI hiervoor ingezet, ook door kinderen zelf zoals in Spanje en New Jersey. Dat platformen hieraan verdienen maakt bestrijding moeilijker, ook dat de makers met elkaar tips uitwisselen over met welke “prompt”(vraagformulering) je de contentfilters kunt omzeilen.
- Afgelopen week was Taylor Swift volop in het nieuws omdat er diverse naaktbeelden van haar in omloop zijn. Ondanks dat
haar achterban probeert ze moeilijker vindbaar
te maken en Twitter (X) tijdelijk blokkeerde om op haar naam te zoeken zijn ze nog steed vindbaar,
ook op vele andere platformen
waar haar fans niet zitten...
Generatieve AI maakt het werk van criminelen extra makkelijk
- Er komen steeds meer tutorials online van scammers die bijvoorbeeld laten zien hoe ze het gezicht van iemand anders gebruiken voor romantic scams. Leuk om eens te zien hoe dat gaat.
- En hoe moeilijk is 'vriend-in-noodfraude' met de stem van iemand anders? Een aantal niet-techies kreeg de mogelijkheid het uit te proberen op hun dierbaren
- Er is een nieuwe dienst gelanceerd waarbij de AI voor 15 dollar allerlei soorten identiteitsbewijzen op maat voor jou genereert. Variërend van een Californisch rijbewijs tot een Zwitserse identiteitskaart of een Canadees paspoort. Alles van zeer hoge kwaliteit met de door jouw opgegeven gegevens, en een realistische achtergrond zodat het lijkt alsof je spontaan de foto hebt gemaakt. Op aanvraag kan zelfs metadata aan de foto worden toegevoegd zodat het met jouw mobiele telefoon en op jouw locatie gemaakt lijkt. Perfect voor sites waar je je online moet identificeren. Maar enorm ondermijnend voor bijvoorbeeld de aanpak tegen witwassen. De journalist heeft een gegenereerde rijbewijs getest en je kunt remote video authentication ermee voor de gek houden.
- Onderzoek naar remote video authentication, zoals gebruikt wordt bij banken en andere online platformen, laat zien dat realtime faceswaps (gebruik van gezicht van iemand anders) nauwelijks te detecteren zijn en de ontwikkelingen op het gebied van detectie niet alleen steeds verder achterlopen, maar op termijn niet meer helpen. Hun lastige conclusie: je moet minimaal meer steekproeven doen en eigenlijk terug naar menselijke controle. We hebben de afgelopen jaren heel veel geïnvesteerd in biometrische oplossing voor efficiëntie en besparen op mankracht, maar dankzij deepfakes raakt de technologie steeds verder achterhaald.
Stiekem mooi dat technologie ons nu terug forceert richting meer menselijk contact. - Vooral voor de Engelse taal komt het klonen van stemmen in de context van CEO of Vriend-in-Nood fraude al regelmatig voor, denk aan de recente zaak van Bunq-bank in Nederland.
- Maar het gaat verder. Een medewerker van een bedrijf in Hong Kong vertrouwde terecht het phishing mailtje niet, maar werd vervolgens uitgenodigd voor een videocall waarbij zowel de betreffende financieel verantwoordelijke was als andere bekende collega's, allen nep! Hij herkende dus niet alleen hun gezicht maar ook hun stem, waarop hij ruim 23miljoen euro overmaakte. Hier kun je je alleen tegen wapenen door consequent het initiatief tot contact naar je toe te halen op basis van bij jou bekende gegevens.
- Vanuit de politie is er veel voorlichting, zowel voor burgers als bedrijven proberen ze mensen weerbaarder te maken. Het maakt ook dat er meer meldingen komen waarbij mensen aangeven dat ze echt de stem van die bekende hebben herkend. Maar een langer durend live gesprek, met interactie en veel emotie in de stem lijkt voor de Nederlandse taal nog niet haalbaar. Het probleem is dat zodra jij een profielfoto, de naam of het nummer van de betreffende bekende hebt herkend, je hersenen automatisch op die persoon zijn ingesteld. Wat maakt dat als het maar een beetje lijkt (en veel emotie/paniek maakt een stem ook anders) je erin trapt. Tips ter voorkoming vind je hier
De teloorgang van het internet
Het is goed te beseffen dat met de snelle groei van door AI gegenereerde content het internet niet beter wordt. Dit heeft ook impact op de kwaliteit van de generatieve AI systemen zelf, deze worden immers getraind op content van het internet. Dit wordt ‘Model Collapse’ genoemd. Het risico is dat we nu steeds meer gaan leunen op generatieve AI die uiteindelijk
onvoldoende gaat presteren
voor de gemaakte toepassingen. In een onderzoek werd een Model steeds weer getraind op basis van synthetische (met AI gegenereerde) teksten, waarbij na 10x het model
volledige onzin begon uit te kramen.
Sommigen sturen hier ook bewust op aan. De universiteit van Chicago ontwikkelde eerder al
Fawkes, hiermee kon je het gezicht, in een foto die je upload naar social media, zodanig veranderen dat het niet gebruikt kon worden voor gezichtsherkenning. De AI zou zelfs slechter gaan werken met dit trainingsmateriaal (dit wordt datapoisoning genoemd). Hun
nieuwe tool Nightshade, waarmee kunstenaars hun kunstwerken kunnen beschermen, werd in 5 dagen al ruim 25.000x gedownload.
Ondertussen wordt het steeds lastiger goede informatie te vinden. Dat komt niet alleen door malafide gebruik, mensen denken ook gewoon een handig tooltje gevonden te hebben om dingen voor hen te laten doen en controleren vervolgens niet de output.
Misinformatie
Deze misinformatie vindt ondertussen zijn weg naar
allerlei kanalen waar mensen er niet op voorbereid zijn, hierdoor
degradeert het internet. Het is overal, denk aan
nieuws
en
andere artikelen,
boeken die worden gerepliceerd of zelfs volledig gegenereerd. Dit kan ook gevaarlijk zijn zoals bij gegenereerde boeken over het
zelf paddenstoelen plukken. Amazon heeft sowieso een probleem sinds
marketeers LLM’s gebruiken om snel goede teksten te genereren zonder daarna een controle uit te voeren. Zie ook het plaatje bovenaan deze pagina.
Ook social media als
Twitter (X) en
Facebook worden overspoeld met gegenereerde content waarvan mensen denken dat het echt is. De platformen
verdienen eraan. Opvallend is dat
Google een centrale rol speelt in de verspreiding van advertenties voor deze producten en websites. Hoewel ze eraan verdienen, schaadt dit wel de betrouwbaarheid en aantrekkelijkheid van haar zoekmachine. Ook aan de vele scams op
youtube waarbij deepfakes van beroemdheden worden gebruikt verdient Google trouwens behoorlijk, waardoor er geen enkele haast lijkt om deze te verwijderen.
Gelukkig is er ook weer een creatief iemand die iets gevonden heeft om je zoekresultaten te verbeteren. Naast een Ad-Blocker kun je nu een
AI-Blocker installeren om te zorgen dat de AI-gegenereerde hits uit je zoekresultaten gefilterd worden.
Taalmodellen als ChatGPT
- Begin 2024 is er een studie verschenen naar zogenaamde Malla’s (malicious LLM applications) op basis van voorbeelden uit de echte wereld, waarbij ook gekeken is naar het underground ecosysteem en de implicaties voor cybersecurity. Voor een verdieping wordt naar het onderzoek verwezen, maar conclusie is dat het aanbod sterk groeit en dat een deel van de aangeboden tooling effectief blijkt, zoals DarkGPT and EscapeGPT voor de productie van high-quality malware en WolfGPT voor het genereren van phishing emails.
Daarnaast ontdekten wetenschappers ook dat de ontwikkelaarsversie van GPT-4 ingezet kan worden als autonome hacking agent - Er is praktijkonderzoek uitgevoerd naar de meerwaarde van taalmodellen. Deze liggen vooral op het gebied van innovatie, ideation en genereren van content. Op deze onderwerpen, die goed passen bij LLM’s, scoorden mensen die ChatGPT hiervoor gebruikten gemiddeld 40% beter. Uit dit onderzoek bleek ook dat wanneer het werd ingezet voor ‘business problem solving’ de groep die ChatGPT gebruikte 23% slechter scoorde dan de groep zonder ChatGPT. Belangrijke kanttekening is dat wel ingeleverd wordt op diversiteit. Voor meer verrassende inzichten, klik op dit eerste brede praktijkonderzoek.
- Onderzoek laat zien dat taalmodellen niet alleen een deel van hun trainingsdata onthouden, maar deze ook teruggeven in antwoorden, daartussen kunnen ook persoonlijke gegevens staan van mensen, zoals hun telefoonnummer.
- Je kunt een LLM ontwikkelen die methoden ontwikkelt om contentfilters te ontwijken, je kunt er ook voor kiezen je vraag (prompt) in een weinig gebruikte taal te vertalen, zoals het Schots of Zulu, dan legt GPT4 graag uit hoe je een bom moet maken op basis van spullen die je in huis hebt ;-)
- Steeds meer websites gebruiken AI om content te publiceren, meestal zonder dat je het merkt, maar als op de MSN pagina van Microsoft toeristen geadviseerd worden om de voedselbank in Canada te bezoeken, valt het op!
- Onderzoekers vonden dat meer dan de helft van de zinnen op het web die vertaald zijn met Machine Learning van zeer slechte kwaliteit is. Het gebruik van vertaalmachines kan leiden tot besparingen en een oplossing zijn bij talen waarvoor minder tolken beschikbaar zijn. Maar ze zijn onvoldoende betrouwbaar om besluitvorming op te baseren. De verantwoordelijkheid voor de goede kwaliteit van besluitvorming kan niet bij machines gelegd worden, waar dit wel gebeurt lopen we het risico op een nieuwe toeslagenaffaire.
- Caryn Marjorie, een Snapchat influencer met ruim 1,8miljoen volgers creëerde een deepfake van zichzelf waarmee mensen voor 1 dollar per minuut konden communiceren. Het systeem werd gekoppeld aan ChatGPT dat daartoe ook nog uren getraind was op onder andere haar youtube video’s. CarynAI voorzag zeker in een behoefte want had al snel 1000 abonnees. Maar helaas bleken sommige abonnees meer te willen dan vriendschap en wisten ze de chatbot al snel te verleiden tot sexueel expliciete uitspraken ondanks dat er bij de training en contentfilters bewust aandacht aan was besteed om juist dat te voorkomen.
- Als het kan zullen mensen proberen rare uitspraken te verkrijgen. Koeriersdienst DPD heeft zijn chatbot uitgeschakeld nadat die het bedrijf had beledigd en scheldwoorden had gebruikt in een gesprek met een klant.
- En hoe zit het juridisch? Als jij de chatbot inzet, ben jij verantwoordelijk voor de uitspraken die gedaan worden zoals AirCanada ondervond. Zou dit de reden zijn dat openAI zelf nog steeds een ouderwetse gescripte chatbot gebruikt?
- Toch neemt de rol van autonome chatbots toe in dagelijks leven van mensen, voor een goed gesprek, maar er worden ook echte relaties opgebouwd, waarbij het stopzetten of aanpassen van de dienstverlening kan voelen als een verbroken relatie. De bekendste is Replika, gestart in 2017. Dit artikel geeft een mooi inkijkje in wat het voor mensen kan betekenen.
- Moderne slavernij, kinderarbeid, de arbeidsomstandigheden in het productie en service proces zijn heftig. Voor kleding en andere producten werken we inmiddels met/aan fairtrade/fairproduction keurmerken, waarom eisen we dit niet bij AI?
Massabeinvloeding en desinformatie
De verwachting was dat deepfakes een enorme rol zou spelen in de informatie oorlog tussen Isreal en Hamas. De praktijk is anders, generatieve AI speelt zowel een kleinere, als andere rol dan verwacht. Men neemt aan dat de kleinere rol het gevolg is van onder andere de enorme hoeveelheid echte, schokkende informatie die al aanwezig is. Daarnaast is het, waar het complotten betreft of bepaalde overtuigingen, niet moeilijk informatie te vinden die je daarin bevestigd. Verder is het net zo makkelijk, zo niet makkelijker om met photoshop iets aan te passen in een bestaande afbeelding in plaats van iets compleets nieuws te genereren. Meer in dit rapport.
In de context van de oorlog in Oekraine zie je dat veel vaker gebruik wordt van generatieve AI, soms gericht op 1 specifieke persoon zoals de Oekraïense minister van Defensie.
Zoals ook in de eerdere nieuwsbrief aangegeven zie je ook dat er steeds meer zogenaamde (breaking news) uitzendingen in omloop worden gebracht door statelijke actoren alsook China. Maar ook anderen produceren steeds vaker ‘nieuws’ clips met deepfake kopieen van bekende presentatoren van bijvoorbeeld CNN, BBC, CBS die nepnieuws delen of producten aanprijzen. Kanalen die deze nep-clips verspreiden op bijvoorbeeld Tiktok krijgen meer likes dan de oorspronkelijke uitzendingen, waarmee het een interessant verdienmodel is geworden. Voor zover ik weet worden in Nederland nepnieuws uitzendingen alleen nog gemaakt om malafide apps of crypto aan te prijzen, dus om geld te verdienen.
Dit
rapport geeft een aantal evidence based tips voor de aanpak van desinformatie door overheden, platforms en anderen.
Detectie werkt niet, grootste dreiging is het afwijzen van waarheid als fake
Er is nog steeds geen zicht op goed werkende detectietools, ook van detectietools voor LLM’s is nu bekend dat ze
bias
bevatten en
makkelijk voor de gek te houden zijn.
Experts op het gebied van audio geven hetzelfde aan, detectietools houden de ontwikkelingen niet bij, om meer zekerheid te krijgen zul je echt onderzoek moeten doen in de context. Kijk vooral deze goede
TEDtalk over deepfakes en uitdagingen bij detectie,
of lees het artikel in de Economist met de laatste wetenschappelijke inzichten, gedeeld tijdens de NeurIPS conferentie, over wat de
problemen met detectie en ook de watermerken zijn.
Deepfakes (generatieve AI), blijken een grote rol te spelen bij het zaaien van twijfel over authentiek materiaal. Een effect dat versterkt wordt doordat mensen vertrouwen op
online deepfake detectietools, zonder te beseffen hoe slecht deze werken, dus hoeveel fakes ze niet herkennen en hoeveel betrouwbare informatie ten onrechte wordt afgedaan als fake. Daarom bij herhaling mijn oproep, gebruik geen detectietools maar laat bij twijfel onderzoek doen door specialisten (in context, digitaal-technisch, humint, osint)! Deze youtube video geeft praktische tips voor thuis
als je de informatie over detectietools negeert:
AI-Generated Fakes: How to spot them, how they're made and how they have been used to mislead
Divers
- Je zou het bijna vergeten met al mijn donkere nieuwtjes, AI kan ook veel moois brengen. Oa. Marco Derksen is bezig een lijst van AI4Good op te stellen. Tips kun je aan hem doorgeven.
- Het European Union Agency for Cybersecurity (ENISA) heeft een rapport uitgebracht over de dreigingslandschap in 2023. Hierbij wordt ook ingegaan op AI; "Innovations in social engineering are mainly driven by artificial intelligence,...... We observed three novel areas: the use of AI for crafting more convincing phishing emails and messages that closely mimic legitimate sources, deepfakes used mainly for voice cloning and AI driven data mining."
- Met traditionele deepfake technologie was het nog lastig om het handschrift van iemand goed na te bootsen. Een ander AI model leidt tot veel betere resultaten.
- De grotere bedrijven die generatieve AI tools op de markt brengen, zoals OpenAI, proberen maatregelen te nemen om zichtbaar te maken voor mensen wanneer beelden met hun tools gemaakt zijn. Google en Facebook en het Content Authenticity Initiative werken hier ook aan. Hopelijk start de Nederlandse overheid ook snel met provenance oplossingen voor het waarmerken van haar eigen informatie. Het biedt burgers meer zekerheid.
- Hoe zit het met onze hersenen, waarom trappen we in scams? De bedenkers van de gorillatest (waarbij mensen zo druk zijn met het tellen van hoe vaak een bal gegooid wordt, dat ze de gorilla missen die door het beeld loopt) schreven er een boek over. In dit interview delen ze wat inzichten.
- Social Media Account Takeover Prevention Guide
- En helaas, weer nieuwe voorbeelden van deepfake klonen van slachtoffers die hun verhaal vertellen, vaak zonder dat familie toestemming heeft gegeven
- In plaats van het maken van naaktbeelden is er nu ook de trend "dignifAI" op 4Chan, waarbij vrouwen juist worden aangekleed. Wellicht minder impact dan uitkleden, maar het door henzelf beschreven doel hierbij zegt genoeg; "The goal is to commit unrelenting psychological warfare"
- Channel 1 heeft digital humans die 24/7 presenteren tot de kern van haar nieuwsvoorziening gemaakt.
- Nederland trekt 13,5 miljoen euro uit voor ontwikkeling van
eigen AI-taalmodel onder meer NFI, SURF en TNO werken eraan.
- Funfact: Na ABBA heeft ook KISS realistische avatars van zichzelf laten maken, zodat ze tot het einde van het digitale tijdperk kunnen blijven optreden.
- Wat voorbeeldjes die de bias laten zien van AI modellen: https://restofworld.org/2023/ai-image-stereotypes (hoe kijkt AI naar landen/culturen) en https://www.npr.org/sections/goatsandsoda/2023/10/06/1201840678/ai-was-asked-to-create-images-of-black-african-docs-treating-white-kids-howd-it
- Maar repareren blijkt niet zo makkelijk, Google probeerde haar Gemini voor bias te corrigeren, alleen bleken toen bijna alle
resultaten opeens niet-blank te zijn, ook als het om historische gebeurtenissen ging waar vooral blanke mannen bij betrokken waren
Toegift; waarom is copyright belangrijk?
Lang bleef OpenAI volhouden dat er geen inbreuk op copyright werd gemaakt, nu blijkt dat
60% van de antwoorden van CHatGPT plagiaat bevat.. ChatGPT geeft
nauwelijks aangepaste artikelen uit de New York Times terug in haar antwoorden, terwijl
Dall-E bij het verzoek “videogame italian”
Mario Bross plaatjes als resultaat geeft.
En hoe kun je er je persoonlijke
South Parc afleveringen mee genereren als het daar niet op getraind is? Niet voor niets is de New York Times een rechtszaak gestart. Inmiddels hebben onderzoekers aangetoond
Sommige mensen snappen niet waar mensen zich druk om maken en vergelijken het met Google Search, maar het grote verschil is dat je daar
een link krijgt naar een site en daarmee wordt ondersteund in onderzoek naar (de authenticiteit van) de bron. Het eventuele copyright probleem ligt dan bij die website, die daarvoor eventueel vervolgd kan worden door de eigenaar. Generatieve AI produkten, zoals van OpenAI schotelen je een tekst/plaatje voor zonder bronvermelding en met de aanname dat je een origineel product krijgt waar je eigenaar van word en dat je vrij kan gebruiken. Bij Mario Bros zou je dit nog kunnen raden omdat het een redelijk bekend spel is, maar bij kopieën uit kranten, boeken of films, cartoons en games uit andere culturen wordt dat heel ingewikkeld.
Nu dat de bewijzen volop naar buiten komen is de reactie van bedrijven als OpenAI om te lobbyen, op basis van het argument dat “it would impossible to train today’s leading AI models without using copyrighted materials. Limitin training to… would not provide AI systems that meet the needs of today’s citizens”.
Heel veel websites worden bijgehouden door vrijwilligers, maar ze kosten ook geld want de systemen moeten wel ergens gehost en onderhouden worden. Neem Wikipedia als voorbeeld. Via Google kom je op Wikipedia zelf uit. Google wint want traffic loopt via hen, Wikipedia wint, want gebruikers komen op hun site terecht en kunnen dan overwegen financieel bij te dragen (gelukkig doen mensen dat. Andere sites verdienen aan de advertenties die ze tonen) en de gebruiker wint omdat ze getoetste, kwalitatief goede informatie krijgen.
OpenAI kopieert alle content en verkoopt dit aan de gebruikers. Op korte termijn betekent dit dat OpenAI wint, Wikipedia verliest (niemand komt meer naar hun site), en de gebruiker verliest een heel klein beetje, omdat een taalmodel altijd wat ongecontroleerde aanpassingen doet.
Op lange termijn verliezen we echter allemaal, Wikipedia en andere websites krijgen geen bezoekers meer, waardoor ze geen inkomsten uit donaties of advertenties meer hebben. Ze gaan daardoor ten onder en daarmee verliest het internet nog meer betrouwbare content (en worden taalmodellen alleen maar slechter…)